
AI-løsninger vurderes ofte på baggrund af deres evne til at lave præcise forudsigelser med nye data, hvad enten de er sat i verden for at forudsige kunder, der enten forlader en forretning eller opsiger deres abonnement, eller salgstal for næste kvartal. I takt med de seneste års rivende udvikling inden for AI og machine learning, der har medført nye muligheder for automatisering af vigtige beslutningsprocesser, er der opstået et øget fokus på det, der ofte kaldes ’explainable AI’ eller ’XAI’.
Hvorfor siger modellen, som den gør?
Begrebet explainable AI defineres forskelligt afhængigt af, hvem man spørger. For os, handler det ganske enkelt om følgende:
- At anvende metoder til at forklare AI-/machine learning-modellers output
- At uddrive indsigter om modellerne og de data, der indgår i modeltræningen
- At skabe transparens og tillid til beslutninger med AI-komponenter
Ved at være i stand til at forklare hvad en AI-løsning rent faktisk gør under kølerhjelmen, kommer man ud af ’the black box’ og skaber samtidig transparens og tillid hos forretningsbrugere samt værdifuld viden, som de kan agere på.
I udviklingsfasen hjælper metoder inden for explainable AI modeludviklere til bedre at forstå forretningen og problemet, der skal løses. Denne viden er ofte ganske nyttig og kan hjælpe udviklere til at bygge bedre modeller. Efterfølgende kan explainable AI hjælpe forretningsbrugere til at forstå en models output og hvilken indflydelse, de forskellige inputvariable har på dens forudsigelser. Mange AI-løsninger er såkaldte ’black box’-modeller, hvor man reelt ikke ved, hvad der sker mellem input og output. Men det behøver ikke nødvendigvis at være sådan. Det er i dag blevet væsentligt nemmere at granske mange typer af modeller for at få svar på vigtige forretningsspørgsmål. I de følgende afsnit vil vi kigge nærmere på, hvad forklarlighed inden for AI betyder samt hvilke typer af information, man kan uddrive fra AI-/ML-modeller.
Når data er guld - de enkelte variables vigtighed
Både for modeludviklingen og formidlingen af indsigter er det som oftest væsentligt at kunne se nærmere på, hvad de mest værdifulde data er. Der findes forskellige metoder til at uddrive såkaldte ’feature importances’ afhængigt af modeltype. Fælles for dem alle er, at de søger at illustrere, hvor meget de enkelte inputvariable bidrager til modellens output – med andre ord; hvor stor prædiktiv værdi de forskellige variable har. Denne viden giver mulighed for en mere målrettet processering af data og videreudvikling af modeller i en iterativ proces. Samtidig giver det forretningsbrugeren et enkelt overblik og viden om hvilken information, der har størst betydning for modellens output. Vigtigheden af variablene fortæller altså hvor ”guldet er gemt”, men med en ret så væsentlig begrænsning; man kan ikke alene på denne baggrund sige noget om, hvordan en given variabelværdi påvirker en models forudsigelser. F.eks. kan en beregning af variablenes vigtighed afsløre, at alder og anciennitet er vigtige faktorer i forudsigelsen af medlemsflugt hos en abonnementsforretning, men ikke hvor meget sandsynligheden for at miste et medlem påvirkes af alder og anciennitet. Samtidig fortæller variabelvigtighed heller ikke noget om, hvorvidt sandsynligheden stiger eller falder, jo højere alder eller anciennitet et medlem har.
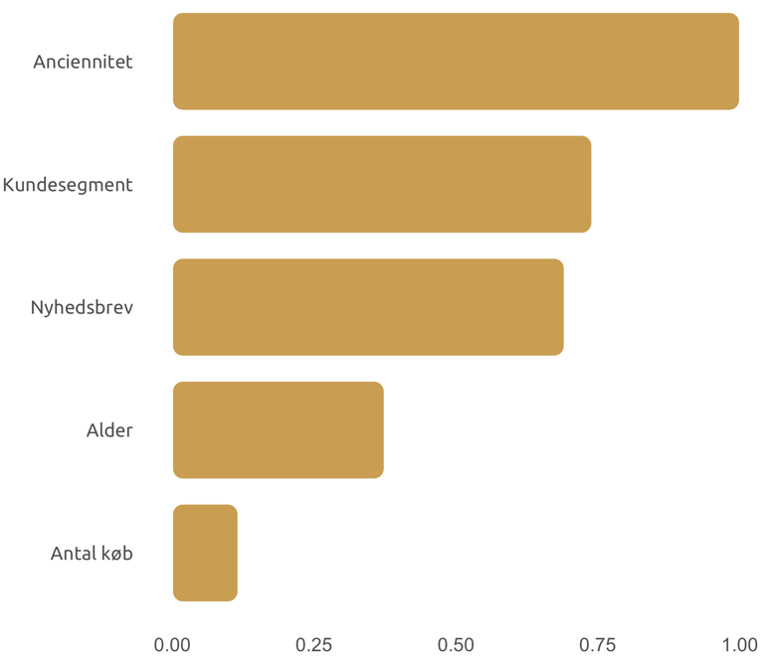
Figur 1 Feature importance.
I grafen ovenfor vises de vigtigste variable for en model, der forudsiger kundeflugt (churn) hos en fiktiv virksomhed. Vi kan se, at variablen ’Anciennitet’ har størst prædiktiv værdi for modellen efterfulgt af ’Kundesegment’ og ’Nyhedsbrev’. Værdierne er skalerede således, at den vigtigste variabel får værdien 1.
Hvis du vil vide mere - globale og lokale forklaringer
Det er naturligvis altid godt at vide, hvilke variable der har størst værdi for en model og bidrager mest til dens forudsigelser. Derudover giver det ofte endnu større værdi at grave lidt dybere og få svar på spørgsmål som ”hvilken betydning har kundens alder for risikoen for churn?” eller ”er risikoen højere eller lavere afhængigt af, om man er mand eller kvinde?”. Denne type af indsigter kaldes ofte ’globale effekter’ eller ’forklaringer’ og kan give forretningen svar på deres konkrete hypoteser og bidrage til formuleringen af strategi og handling forankret i data. Hvor de såkaldte ’feature importances’, forklaret ovenfor, giver et overblik over de vigtigste data for en model, viser de globale forklaringer hvordan og i hvilken retning, variablenes værdier påvirker modellens forudsigelser.
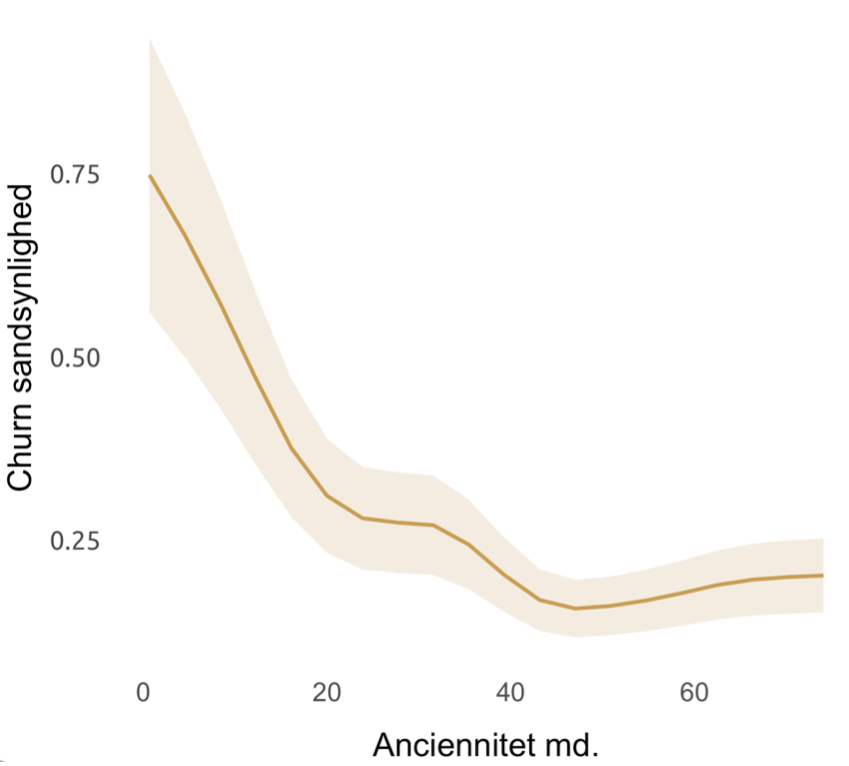
Figur 2 Globale forklaringer.
I grafen her ser vi, hvordan kundernes anciennitet påvirker sandsynligheden for churn, når alle andre variable holdes konstante. Det ses tydeligt, at sandsynligheden falder markant de første måneder, hvorefter den gradvist flader ud i takt med stigende anciennitet.
Foruden de globale effekter, der skal illustrere sammenhænge mellem prædiktioner og værdier inden for de enkelte inputvariable, er det tilmed også muligt at forklare de enkelte forudsigelser og forstå hvilke variabelværdier, der f.eks. trækker en sandsynlighed for churn eller et salgsestimat op eller ned – altså de lokale forklaringer. Denne viden kan eksempelvis bruges i retail- og abonnementsforretninger til at optimere kundeinteraktion, så man i højere grad kan sende de rette budskaber til de rette kunder baseret på viden fra modellen. Et andet eksempel kunne være i produktions- og forsyningsbrancherne, hvor man benytter predictive maintenance-modeller til bl.a. at forudsige nedbrud og fejl i teknisk udstyr. Her kan de lokale effekter fortælle, hvorfor modellen mener, at der vil ske et nedbrud af en maskine eller andet udstyr.
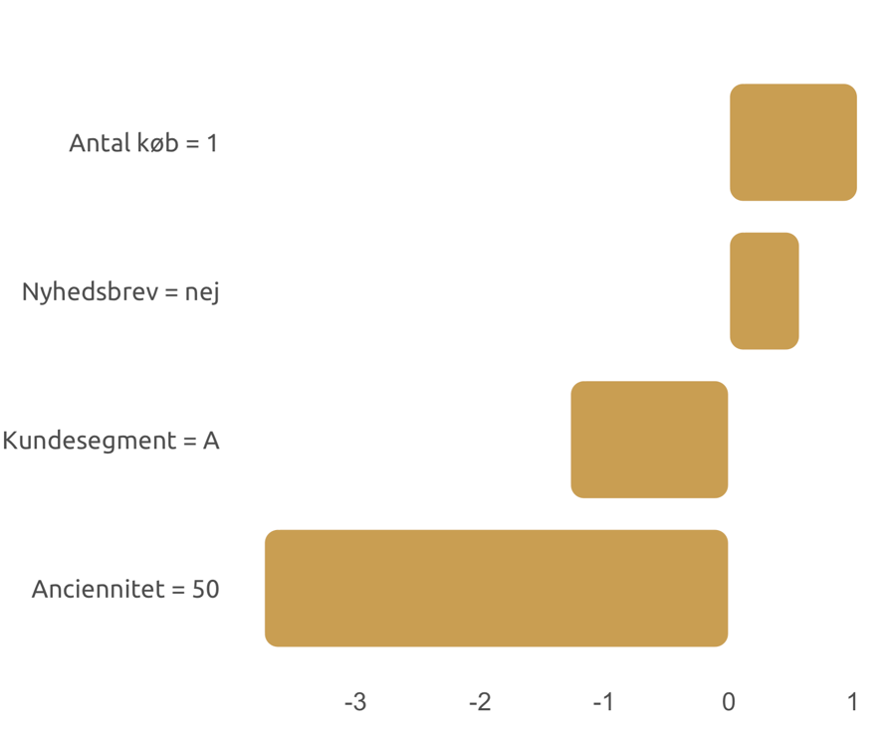
Figur 3 Lokale forklaringer.
I eksemplet på en lokal forklaring ovenfor ser vi, hvordan en prædiktion for en enkelt kunde påvirkes af forskellig information om den pågældende kunde. Vi ser blandt andet, at et lavt antal køb ”taler for” for churn, mens kundens høje anciennitet klart trækker sandsynligheden for churn ned.
Ansvarlighed og sikring af fairness
For virksomheder der anvender AI-løsninger, der berører almindelige mennesker, er det særligt vigtigt at forebygge diskrimination baseret på f.eks. køn eller etnicitet. Når man er i stand til at forklare, hvordan en model virker, og hvad den faktisk gør, når den behandler nye data, kan man også bruge disse indsigter til at sikre, at modellen træffer fair beslutninger, der ikke er til ulempe for særlige befolkningsgrupper. Her gælder det ikke længere om at opnå den bedst mulige modelperformance, men snarere den bedst mulige performance givet, at modellen er fair. I mange tilfælde vil det dog ikke være tilstrækkeligt at undlade at anvende demografisk information om f.eks. etnicitet direkte, når der trænes en model. Sådanne følsomme informationer kan nemlig ligge skjult i anden information om et individ. Man kunne således forestille sig, at en model til kreditvurdering, der anvender geografiske data, kan give unfair estimater baseret på etnicitet, hvis der er klare sammenfald mellem visse områder og etnicitet.
Eksempler på brancher og use cases, hvor det kan være vigtigt at overveje sikring af fairness i modellerne:
- Forsikring - behandling af sager
- Finans – lån og kreditvurdering
- Sundhed - patientklager og behandlingstilbud
Tillid hos forretningen betyder alt
Det er naturligvis ikke alle AI-løsninger, der behøver at drage nytte af explainable AI-komponenter. I mange tilfælde er det dog et vigtigt element - ikke bare i forståelsen hos forretningsbrugere, men også i selve tilliden til anvendelsen af AI i vigtige forretningsopgaver og beslutninger i det hele taget. Hvis ikke der er tillid, vil løsningen sandsynligvis ikke bruges i samme udstrækning og dermed aldrig for alvor blive en succes for forretningen. Brugernes tillid til hvad modellen fortæller er derfor en nødvendighed for at lykkes med AI-projekter. Det er derfor vigtigt, at de relevante dele af forretningen er med fra start, når der udvikles AI-løsninger. Ved at inkludere brugerne, kan man bl.a. øge tilliden ved at bruge deres unikke viden og erfaring til at formulere hypoteser om, hvad der potentielt kunne drive en models beslutninger. Den færdige model vil efterfølgende kunne give svar på hypoteserne og være en stor hjælp i modeludviklingsfasen til at undgå fejl og utilsigtet bias.
Efterspørgslen på AI-løsninger, der involverer indsigter skabt med explainable AI-metoder, vil formentlig kun vokse i fremtiden, hvor flere og flere virksomheder får øjnene op for mulighederne, som explainable AI giver. I brancher som f.eks. sundhed og finans, hvor beslutninger påvirker almindelige menneskers liv, kan der endda være tydelige krav til, at samtlige forudsigelser lavet af AI-/ML-modeller i produktion skal være transparente og kunne forklares på troværdig vis.
Hensigten med dette indlæg var at give en kort introduktion til, hvordan metoderne bruges i udviklingsfasen til at validere modeller og data og til at sikre, at forudsigelserne er fair og laves på et korrekt og ansvarligt grundlag. Ligeledes kan virksomheder og slutbrugere få stor gavn af at kunne finde svar på, hvorfor modellen siger, som den gør. I sidste ende handler det om transparens og tillid, og det er netop det, der skal til for at skabe succes med AI og machine learning – ikke mindst når disse teknologier bruges til at træffe automatiserede beslutninger.