
”AI indleder industri 4.0”, ”Machine learning er fremtiden” og ”Data er det nye guld”. Der mangler ikke just blogs, der taler Machine Learnings næsten mytiske kræfter op. Man kan nemt komme til at tro, at Machine Learning er lig en autonom kunstig intelligens alla HAL 9000 fra rumrejsen 2001, der baseret på lige dele databjerge og sort magi kan løse alle verdens problemer fra brætspillet GO til kuren af alverdens sygdomme. Men midt i orkanen af buzzwords bliver mange – med rette – skeptiske. For hvad er Machine Learning egentlig? Og hvordan kan det skabe værdi for netop din egen forretning?
Desværre er der langt mellem klare svar på de spørgsmål. Enten møder man en mur af matrixmultiplikationer, hyperparametre og optimeringsalgoritmer ellers ryger man tilbage i hype-sumpen, som man netop prøvede at undgå. I dette indlæg vil vi prøve at ramme den gyldne middelvej mellem buzzwords og backpropagation.
Machine Learning finder møstrer
Konceptet bag Machine Learning er relativt: Machine Learning er en blanding af statistik og algoritmer, der kan finde mønstre i store mængder data. Selvom det på overfladen virker næsten banalt, er implikationerne mange, og man kan vinde meget ved at forstå dem i dybden. Tag fx nedenstående billede, der viser hvordan tre plantearter er delt på to variable (antal blade og bladstørrelse).
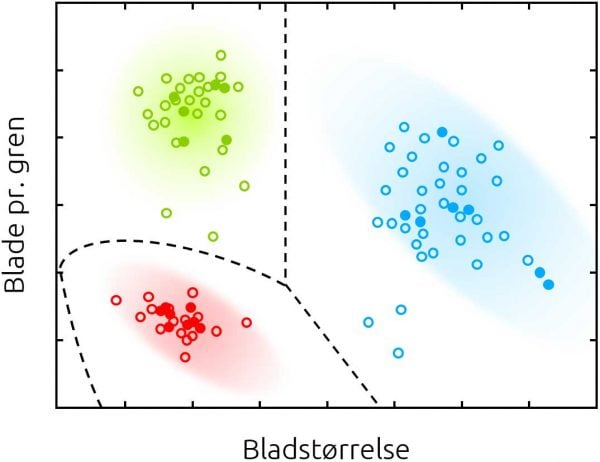
Her har en Machine Learning model fundet den bedste måde at afgrænse de tre arter på (de stiplede linjer). Hvis man herefter ser en ny plante, kan modellen dermed forudsige, hvilken art planten tilhører alt efter, hvor den befinder sig i koordinatsystemet (sammenhængen mellem blad-størrelse og antal blade per gren). Umiddelbart er det dog ikke særligt imponerende – selv et børnehavebarn ville ikke have de store problemer med at tegne streger, der skiller de tre arter ad.
Der hvor Machine Learning for alvor slår igennem er, når problemerne bliver for komplicerede til, at vi mennesker kan overskue dem. Hvis der i stedet for to variable var 20, som fx gren-tykkelse, længde og vandforbrug, samt fem forskellige arter og tusindvis af eksempler, ville det være helt umuligt for et menneske, mens en Machine Learning model ville kunne løse problemet uden at få sved på processoren.
Machine Learning skal lære først
Det ovenstående eksempel falder ind under kategorien klassifikation. Klassifikation er når modellen forudsiger en kategori, som om en mail er spam eller ej, hvorvidt der er en kat på et billede eller hvilket produkt en kunde er mest tilbøjelig til at købe. Det er et af de områder, hvor Machine Learning klarer sig bedst. Det kræver dog, at man har en masse allerede klassificeret data klar, som modellen kan lære af (deraf Machine Learning). Den proces kan ofte være tidskrævende, hvis en ekspert manuelt skal sidde og vurdere en masse observationer.
Potentialet er dog markant. Tænk bare hvor meget tid man kunne spare, hvis alle kunde-henvendelser automatisk blev sendt til den rigtige afdeling (og hvor meget gladere kunderne ville blive for ikke at blive routet fra afdeling til afdeling), eller hvor mange penge man kunne spare på at målrette til lige netop de kunder, der har størst risiko for at falde fra. Klassifikation er dog ikke den eneste kategori af Machine Learning-teknikker, der kan skabe værdi.
Regressionsalgoritmer forudsiger temperaturen i Tønder
En nær kusine til klassifikation er regressionsalgoritmer. Mange kan sikkert genkende regressioner fra Excel, hvor man med et tryk på en knap kan finde en linje gennem nogle datapunkter. Det er lige netop, det regressions-modeller gør – i stedet for at forudsige en kategori, finder den kurven, der bedst følger eller forbinder datapunkterne.
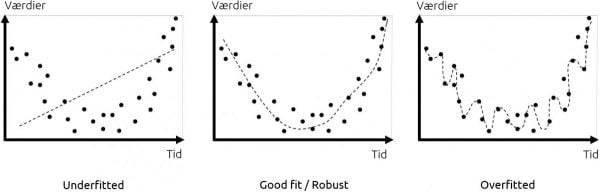
Eksempler på regressioner er fx at forudsige prisen, en kunde er villig til at betale for et produkt eller temperaturen i Tønder i næste uge. Regressioner giver også et godt indblik i en af de mest fundamentale udfordringer i Machine Learning. Regression (og klassifikation) handler nemlig om at forudse eller estimere usete observationer baseret på historiske data. Derfor er der en fin balance mellem at have en for simpel model, der ikke fanger så meget af variationen (det man også kalder at ”underfitte”) og så at have en for kompliceret model, der meget nøjagtigt beskriver de historiske data, men ikke kan generalisere til usete data (også kaldet at ”overfitte”). Forskellen er illustreret på nedenstående figur.
Supervised og unsupervised learning
Fælles for klassifikation og regression er, at modellen i begge tilfælde prøver at finde ”det rigtige svar”. Hvad end man vil finde billeder af katte eller forudsige aktiemarkedet, kan man finde historiske, annoterede data – enten kattebilleder eller tidligere aktiepriser – som modellen kan prøve at efterligne så godt som muligt. Dermed er det også relativt nemt at sammenligne modeller; man kan kigge på hvor stor en andel, som modellen svarer rigtigt. Fordi man ”hjælper” modellen ved at give den de rigtige svar til at lære fra, kalder man disse teknikker samlet for supervised learning. Der er dog en helt anden kategori af modeller, nemlig unsupervised learning.
I unsupervised learning er der ingen annoterede data. I stedet beder man modellen om at inddele datapunkterne i grupper, som den finder passende. Denne form for teknik kalder man segmentering (eller clustering) og nedenunder kan man se et eksempel på en segmentering i aktion.
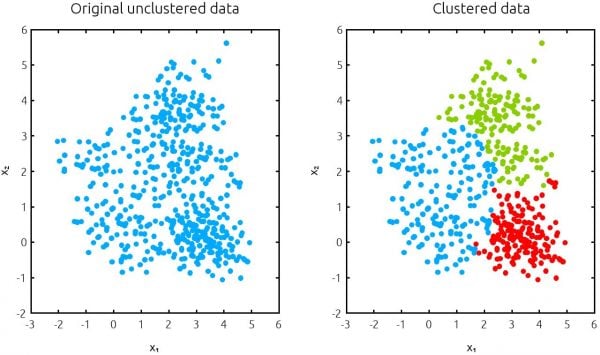
Fordi der ikke længere er nogen rigtige svar, er det også markant sværere at vurdere, hvilken model der laver den bedste segmentering. Det er fx ikke åbenlyst, hvorfor algoritmen har valgt at splitte den blå og grønne gruppe netop der. Det kræver derfor en del menneskelig fortolkning at få segmenterne til at give mening. Af den grund anbefaler man normalt, at man starter med et supervised learning-projekt, når man begynder at lære grundprincipperne i Machine Learning-verdenen.
Machine Learning stjæler ikke dit job
Nu hvor vi har en større forståelse for Machine Learning, er det tid til at snakke om, hvad det ikke er. Machine Learning er ikke lig automatiserede robotter, der overtager jobs. Dog er Machine Learning en vigtig komponent i automatisering, da det bidrager med fx at læse fakturaer, sortere post og spotte svindel. Dog kan det kun hjælpe, hvis en opgave på et eller andet plan er mønstergenkendelse. Langt de fleste opgaver består dog ikke kun af mønstergenkendelse, men også at kunne agere i den virkelige verden, kreative opgaver og en masse andre ting.
Machine Learning er heller ingen magisk boks, hvor man bare kan proppe alt muligt data ind og så få geniale indsigter ud. I og med Machine Learning brillerer ved at finde mønstre, kan det let gå helt galt, og Machine Learning omdanner ikke dårlige eller usammenhængende data til noget det ikke er.
Machine Learning modeller vil forsøge at finde de mønstre de kan i data, men hvis der ikke er et retvisende mønster, kan modellen ikke finde et sådan. En given model vil altid gøre det, den er sat i verden til, nemlig at finde det mønstre i data, men hvis der ikke er et reelt mønster, kan modellen ikke vurdere dette selv. Modellen vil finde det mest oplagte mønster, men det kræver menneskelig fortolkning at vurdere outputtet af en Machine Learning model. Der er derfor en essentiel del af processen, at man sørger for at have godt styr på det data, man giver til modellen og både involverer data- og forretningseksperter.
Hør hvordan vi kan hjælpe med Artificial Intelligence (AI).