
AI (artificial intelligence) og machine learning kan løse enormt mange problemer – og bidrage til et bedre og mere effektivt samfund gennem smartere og optimale arbejdsgange.
Vi har alle set film som Terminator, og selvom der stadig er meget langt til ”Skynet” og maskinernes overtagelse af verdensherredømmet, skal de mere virkelighedsnære AI-løsninger, der integreres tæt med vores samfund og vores måde at agere på, behandles med omtanke. For det er vigtigt, at vi udvikler og udnytter potentialet i AI på en etisk forsvarlig måde.
Formålet, man udvikler sit AI-system til, har stor indflydelse for tilgangen til at udvikle AI ansvarligt. Etisk skal man altid overveje, om det er en brug, man er interesseret i at udvikle til. Det kan f.eks. handle om våbensystemer eller manipulation af befolkningen gennem internetreklamer.
Det er dog ikke altid nødvendigt at lave en større etisk analyse af ens AI-model. Hvis man for eksempel udvikler et system, der tager billeder af et samlebånd for at sortere fejl-produkter eller dårlige æbler fra, eller et system, der optimerer rækkefølgen af træer, der skal fældes i et skovbrug, er det ikke lige så relevant at undersøge, hvorvidt ens model er etisk og ansvarligt udviklet. Dér hvor man skal overveje responsible AI er, når man bruger personfølsomt data, eller hvis ens AI-system har indflydelse på mennesker. Det kan være systemer, der bruger biometrisk data som ansigtsgenkendelse eller systemer, der godkender ansøgninger til forsikringer eller banklån.
Man kan se responsible AI fra flere sider, men vi har valgt at fokusere på tre emner, der dækker de vigtigste elementer og største problemstillinger:
- Explainable AI
- Fairness
- Sikkerhed og robusthed
Explainable AI
Med explainable AI, på dansk forklarlig AI, går man væk fra den tit omtalte ”black-box”-tilgang til machine learning, hvor det er grænsende til umuligt at vide, hvad der egentligt foregår i algoritmen. Med forklarlige algoritmer kan man intuitivt forstå og forklare, hvorfor modellen gør, som den gør, hvilket giver mange fordele. Det skaber bl.a. øget troværdighed af resultaterne, og derudover kan man udnytte, at man ved, hvordan forskellige variable og faktorer har indflydelse på resultatet. Hvis man for eksempel ved, præcis hvordan en variabel som ’alder’ har indflydelse på en forudsigelse af risikoen for opsigelse af et abonnement, kan man bruge denne viden til at lave tiltag, der rammer præcist dér, hvor det har størst effekt. Det kan f.eks. være til gavn for en marketingafdeling. Man kan også bruge denne viden til at udtrække information om sammenhængen mellem ens data og den virkelige verden, hvor data stammer fra, da modellen kan forklare og vise komplekse sammenhænge. Vi har skrevet meget mere om explainable AI her.
Fairness
Begrebet fairness dækker over, at alle skal behandles lige. Med fairness vil vi gerne undgå, at vores algoritme diskriminerer på alder, køn, etnisk oprindelse eller andre demografiske kendetegn. Hvis der er demografisk information inkluderet i data, er der en risiko for, at modellen diskriminerer befolkningsgrupper, men selv hvis demografisk sensitivt data ikke er inkluderet i træningen af modellen, kan modellen stadig finde sammenhænge mellem andre features, der kan lede til diskrimination. Det er altså ikke nok blot at udelade sensitiv information såsom race, køn eller religion fra datasættet. Hvis AI-modellen har indflydelse på individer eller gruppers liv, er der derfor grund til at undersøge fairness af modellen.
For at undersøge fairness og forsøge at mitigere eventuel unfairness i vores model, skal vi først definere, hvad vi mener med fairness.
Dette består af to underopgaver:
- Hvad måler vi fairness på? Er det alder, religion, køn, en kombination - eller noget helt andet?
- Hvordan måler vi unfairness? Kræver vi samme følsomhed, når det gælder om at finde positive eksempler, f.eks. dårlige betalere, som når det gælder om at finde negative eksempler?
Et eksempel kan være nedenstående resultat fra en machine learning-model, der bestemmer, om personen kan blive godkendt til det ansøgte lån.
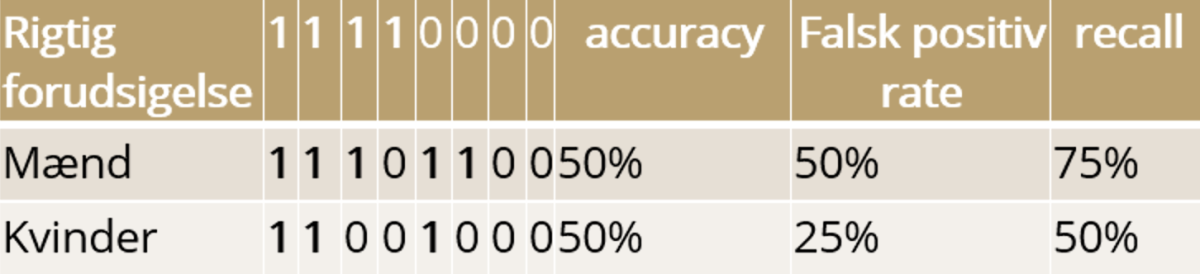
I dette tilfælde har modellen en accuracy på 50% for både mænd og kvinder, så hvis man kun ser på træfsikkerheden, er der altså ingen unfairness i modellen. Falsk positiv rate fortæller, hvor mange der har fået lånet, når de ikke burde have det, og recall beskriver, hvor mange modellen godkender ud af alle, der bør godkendes. Kigger man på falsk positiv rate, er det dog tydeligt, at modellen ikke er helt fair. I eksemplet bliver kvinder nemlig diskrimineret ved både at få færre retmæssige lån godkendt og samtidigt have en lavere mængde uretmæssige lån godkendt end mænd.
Vi ser altså, at fairness ikke kan defineres generelt, men at definitionen kommer an på problemets natur, og hvordan løsningen skal bruges.
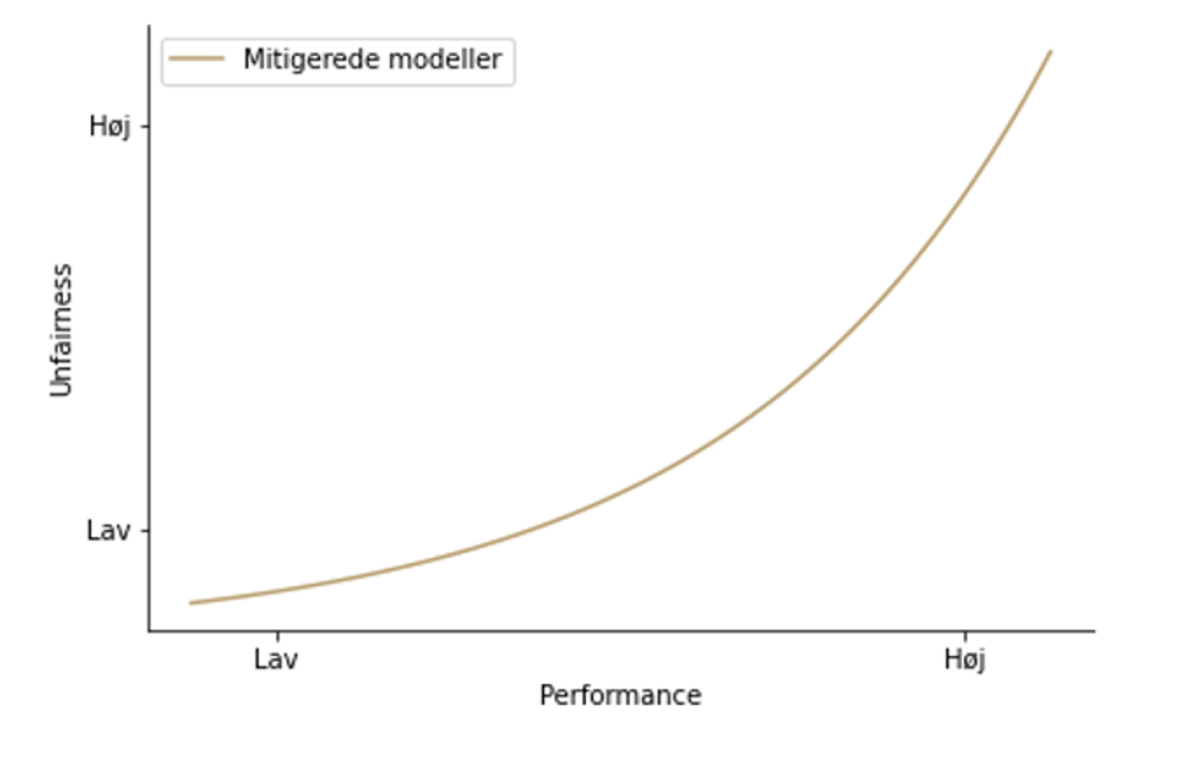
Hvis man i analysen opdager, at ens model diskriminerer bestemte grupperinger, kan man mitigere unfairness. Det gør man ved at vægte de forskellige grupper forskelligt i træningen, så den diskriminerede gruppe får en højere vægt/vigtighed i træningen af modellen. Dette leder til et fald i performance for modellen, og dermed skal man beslutte sig for, hvor balancen mellem fairness og performance går i det specifikke tilfælde.
Som det kan ses i nedenstående plot, vil man skulle vælge en model langs en kurve, der giver et kompromis mellem performance og fairness.
Sikkerhed og robusthed
Sikkerhed er et vidt begreb, der dækker over mange ting. Når AI-systemer bliver brugt i den virkelige verden, har de også en påvirkning derpå. Da AI-systemer ikke er perfekte, er et sikkerhedshensyn at tage derfor at kortlægge og analysere hvilken indflydelse, forkerte forudsigelser kan have. Dette varierer alt efter use-case. En fejl i et oversættelsessystem er meget forskellig fra en potentielt katastrofal fejl i et system til en selvkørende bil eller et system i hospitalsvæsenet.
Da AI-modeller bygger på data, er det også vigtigt at sikre data, så uvedkomne ikke kan udnytte adgangen til data. Hvis en uvedkommen har adgang til data, kan det risikeres, at andre får adgang til personfølsomme oplysninger.
En anden risici er, at en uvedkommen ændrer i data, så modellen efter næste træning kommer med forkerte forudsigelser. Dermed risikerer man, at andre får indflydelse på modellen – og dermed de konklusioner, der bliver draget på baggrund af den.
Udover normal sikkerhed kan man bl.a. sikre sin model og sit data ved at begrænse adgang for fremmede til modellen og dens forudsigelser. Det er også muligt at beskytte følsomt data ved hjælp af såkaldt differential privacy, hvor man tilføjer støj til datasættet, så man ikke kan tilbageføre data til de originale datapunkter. Der findes flere og meget avancerede måder at beskytte data på ved hjælp af f.eks. homomorfisk kryptering, hvor man kan lave beregninger direkte på krypteret data. Det er dog meget tungt beregningsmæssigt og har store begrænsninger i, hvilken type beregninger man kan foretage.
En sidste sikkerhedsbetragtning omhandler robusthed. For at bruge AI ansvarligt, er det vigtigt at vide, at den bliver ved med at opføre sig som forventet i et produktionsmiljø. I Kapacity har vi udviklet et MLOps framework i Microsoft Azure cloud-platformen, der kan tracke og holde styr på versioner af data og modeller, så man kan opdage og analysere ændringer ved hver ny model. Detektering af data drift – dvs. når data, der ligger til grund for modellen, ændrer sig signifikant – er også inkluderet, og det tillader automatisk gentræning, når ny data er tilgængelig. Ved at overvåge modellerne og det data de baseres på, kan man sikre høj operationel sikkerhed og robusthed.
Opsummering
Ansvarlighed i AI er et bredt og komplekst emne, der indeholder mange delelementer, der er mere eller mindre relevante alt efter den pågældende problemstilling. Generelt er det dog vigtigt ved ethvert projekt at overveje, om ens projekt er i fare for ikke at være ansvarligt ud fra forklarlighed, fairness eller sikkerhed.