
Hvad er Microsoft Fabric?
Det kan siges kort: Det er en SaaS løsning for udvikling af dataplatform-løsninger.
Hvad er det nu SaaS er for noget?
Det står for Software as a Service. Og hvad betyder det så? Det betyder, at du bare kan bruge servicen uden at skulle installere den. Du kan f.eks. bruge Outlook uden at skulle installere den. Hvis du skal bruge en SQL-database i dag, f.eks. Microsoft SQL Server, så er den godt nok tilgængelig i skyen, så du skal ikke installere den på din egen server "hjemme i kælderen", men du skal stadig opsætte den - bare i skyen. Du skal vælge størrelsen på den og konfigurere den på forskellig vis. Dertil er du først nødt til logge på selve sky-servicen, Microsoft Azure, og så vælge SQL databasen dér. Med SaaS går du bare i gang med at bruge det, du nu skal bruge. Når vi taler Fabric, skal du bare være almindelig Power BI bruger, så kan du gå i gang. Klik på "New" og vælge "Warehouse" eller "Pipeline" osv. - og så er du i gang i din browser.
Hvad er der inden i Fabric?
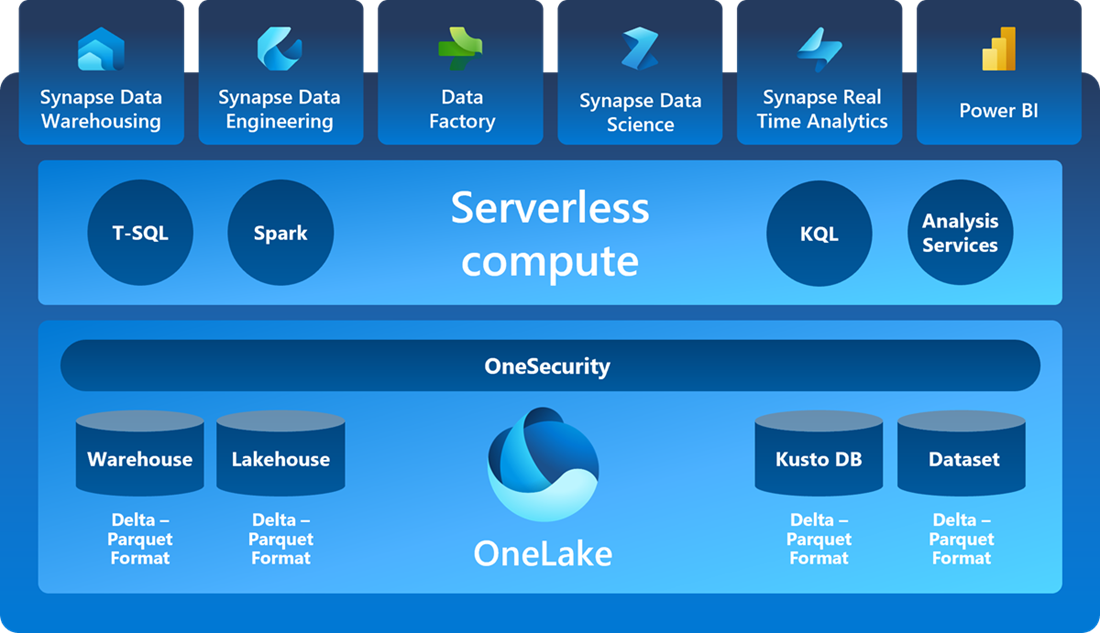
Der er alle de redskaber, der skal til for at bygge en moderne cloud dataplatform: F.eks. Data Pipelines til at få fat i data fra dine datakilder, Synapse Data Engineering notebooks og Lakehouses til at udføre datatransformationer, Synapse Data Warehouses til at skabe et SQL-lag, hvor man kan forespørge på data via SQL, selvfølgelig Power BI datasæt- og rapport-værktøjerne til at skabe visuelle præsentationer af data, og en hel del mere.

Hvad er forskellen mellem Fabric og tidligere udviklingsplatforme?
Der er primært følgende kæmpe forskel: I Fabric har man helt konsekvent adskilt lagringen af data på den ene side og de services, der behandler data, på den anden side og desuden valgt at lagre data i et fælles åbent format: Delta (parquet).
Hvad ligger der så i dette?
Adskillelsen af lagring og de services, der behandler data, kaldes også adskillelse af "storage" og "compute" i dataplatform-terminologien. Eksempel: En SQL database består forenklet sagt af to ting: en maskine, der kan manipulere med struktureret data og så dataet selv. I én samlet pakke. Data "er inden i databasen". I modsætning til denne løsning findes produkter som Azure Databricks, hvis "maskine" til manipulation af data er baseret på et avanceret system af flere computere, der arbejder sammen i et såkaldt Spark-cluster, men selve dataene ligger for sig selv i en data lake, i et slags distribueret filsystem. Her er ”storage” adskilt fra ”compute”. I Microsoft Synapse Analytics har man også hele tiden haft mulighed for at udvikle løsninger baseret på Spark-tilgangen og også her adskille Storage og Compute. Det nye i Fabric er, at man har gjort dette konsekvent over det hele.
I Fabric har man:
- T-SQL Compute, der tilbyder at arbejde med data på helt klassisk relationel tilgang, med SQL, stored procedures osv. i Fabrics Synapse Data Warehouse.
- Spark Compute, der tilbyder at arbejde med data ved hjælp af såvel Python, Scala, R og også SQL gennem notebooks og job i Synapse Data Engineering
- KQL Compute, der tilbyder at arbejde med data ved hjælp af Kusto forespørgsel-sproget (KQL), der bl.a. egner sig til log- telemetri-data analyse (tidsserier)
- Power BI Compute, der tilbyder at arbejde med data særligt velegnet for BI analyse (semantiske modeller)
Fælles for alle disse fire computes er, at det data, de arbejder på, ligger adskilt fra dem (dog har de hver især behov for egne metadata). Og det ligger i Delta-format.
Det betyder at alle compute-typer kan dele data via OneLake. Og man kan også anvende compute fra andre services udenfor Fabric, der forstår delta-formatet, f.eks. Databricks.
Eksempel: Man kan fra et Warehouse foretage en forespørgsel i en salgstabel fra warehouset kombineret med en kundetabel, man måtte have oprettet tidigere i et Lakehouse (selvom vi siger, at der er en salgstabel i warehouset og en kundetabel i lakehouset, er det kun metadata, vi taler om. Selve rækkerne af salgstransaktioner og kundeinformationer ligger helt separat på det underliggende data lake storage).
Eksempel: Power BI har hidtil haft mulighed for at kunne forespørge på data på grundlæggende to måder:
1) "Direct query", hvor Power BI sender SQL-forespørgsler til en SQL-kilde og får svar tilbage, som så skal oversættes og vises.
2) ”Import mode”, hvor data læses fra en anden datakilde ind i Power BI’s eget interne storage i hukommelsen.
De har begge haft begrænsninger enten mht. performance eller funktionalitet. Med introduktionen af Fabric har Microsoft gjort det muligt for Power BI at forespørge på data direkte fra der, hvor det ligger i data lake'en, med fuld funktionalitet og super performance. Dette nye "mode" hedder "DirectLake mode". Med andre ord slipper man for at kopiere data endnu engang til Power BI dataset igennem import mode gennem en refresh for at få god performance på forespørgsler i rapporteringen, så man dermed nemmere kan levere nær-realtids rapportering samt håndtere store datasæt, der slet ikke kan være i hukommelsen i Power BI.
Og hvad er det så for en data lake, man gemmer alt data i?
Dér har Microsoft også skab noget ret interessant nyt. Man har indført konceptet "OneLake". OneLake er en abstraktion oven på allerede eksisterende data lakes. Med hver Fabric-tenant (= Power BI-tenant) kommer der én OneLake, som hele organisationen deler. Når man opretter noget data via et hvilket som helst Power BI workspace (f.eks. henter data ind til behandling i sit Lakehouse eller Warehouse), gemmes det i denne fælles OneLake. Det giver nogle store fordele. Man kan minimere antallet af gange, man kopierer data. Hvis man har de rette adgange, kan man tilgå data direkte fra et givet sted i OneLake'en, hvor der måtte ligge det data, man ønsker at bruge.
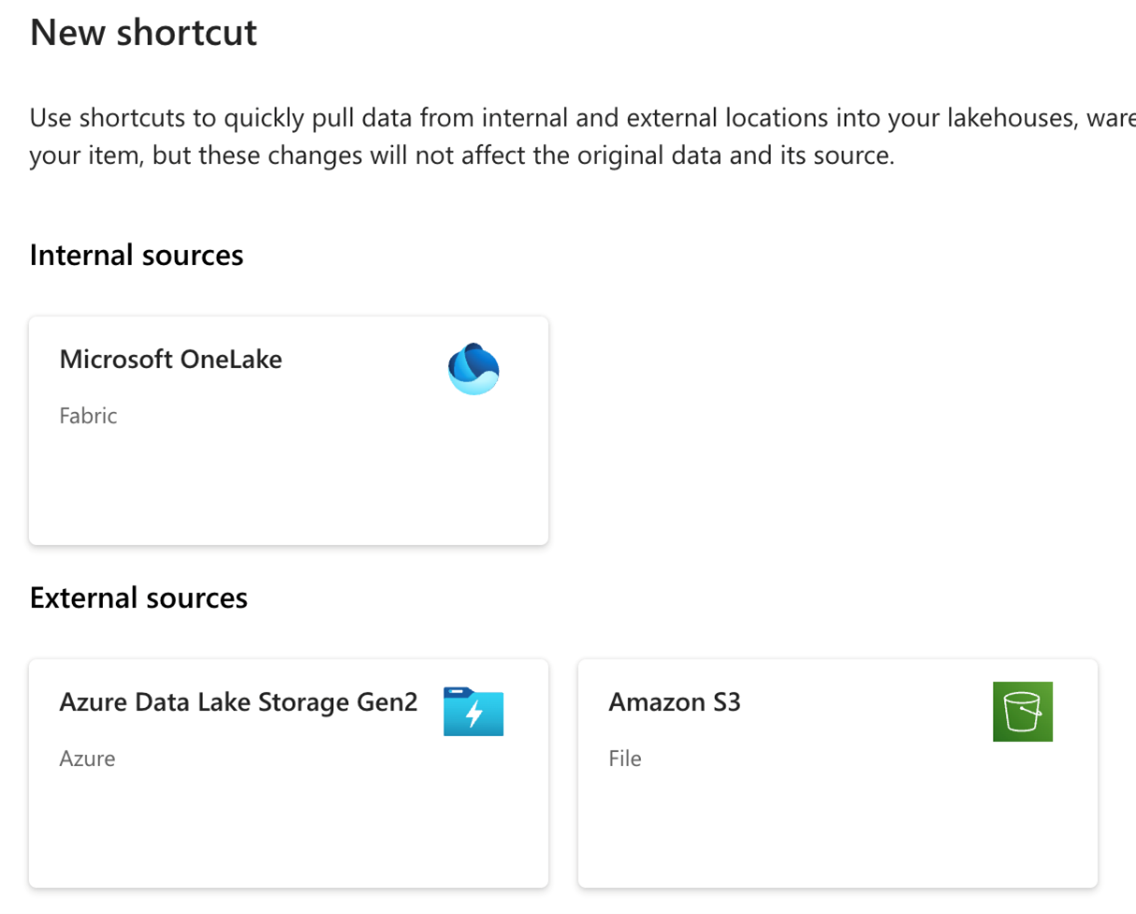
Og med OneLake kan man noget yderligere rigtig smart. Man kan vha. shortcuts oprette links til allerede eksisterende data lakes, herunder Microsoft Azure Data Lake Gen2 og Amazon S3. Igen betyder det, at man slipper for at kopiere data fra disse kilder "ind i sin OneLake". De kommer bare til at se ud, som om de allerede er en del af ens OneLake, så at sige. Med det åbne Delta-format som grundlag fungerer det lige så fint for Fabric at læse data fra en ekstern data lake som fra selve OneLake'en.
Det lyder lidt som kaos med sådan en fælles OneLake - er det det?
Der er allerede fra lanceringen af Fabric en del governance muligheder, så som adgangstyring via workspaces, men der kommer meget mere. Microsoft har annonceret en ensartet sikkerhedsmodel, der kommer til at dække på tværs af hele Fabric.
Vi har allerede bygget en dataplatform baseret på Databricks eller Synapse Analytics. Skal vi nu starte forfra?
Dertil kan vi fra twoday Kapacity sige følgende nu og her:
- Vi kan sagtens se scenarier, hvor man bliver, hvor man er, og scenarier, hvor man kombinerer eksisterende løsninger med dele af Fabric (f.eks Databricks og Fabric sammen - husk data er i Delta-format og kan deles på tværs, så data tilrettelagt i Databricks kan læses af Fabric, eller man kan fra Databricks skrive direkte ind i OneLake), og scenarier hvor man starter nye projekter på Fabric.
- Microsoft har på ”Microsoft Build”-konferencen annonceret en kommende migreringsmulighed fra Synapse Analytics Dedicated SQL pools, hvis man faktisk skulle ønske at migrere.
- Hvis du ønsker at finde ud af om Fabric er noget for dig, så start med at eksperimentere med et område – byg en Proof-of-Concept løsning. Husk, at lige nu er Fabric i preview, og der vil være fejl, der skal rettes, der vil komme performanceforbedringer og der vil komme flere features.
Kontakt os her, hvis du ønsker mere information om Fabric.