
NB: Dette blogindlæg er oversat fra engelsk. Læs det oprindelige indlæg her.
Microsoft annoncerede i slutningen af 2020, at Azure Synapse Analytics nu har opnået General Availability, hvilket vil sige, at platformen nu er tilgængelig for alle. I dette blogindlæg kigger vi bl.a. nærmere på den nye platforms komponenter, funktioner og sikkerhed.
Det er i dag vigtigere end nogensinde at kunne skabe indsigt i sin forretning på baggrund af data. Derfor kommer virksomheder typisk til at ligge inde med store mængder af data. Data, som skal indhentes, lagres og analyseres på en hurtig og effektiv måde.
Gennem årene er der kommet mange bud på teknologier, som kan hjælpe virksomheder med ovenstående. Problemet er blot, at disse teknologier er usammenhængende og ikke altid er designet til at blive forbundet og integreret på en nem måde. Dette ligger bl.a. til grund for, hvorfor Microsoft i 2015 begyndte på udviklingen af Azure Synapse Analytics – en samlet platform, som skulle være fyldestgørende for den moderne dataplatform med alle de nødvendige kernefunktioner – uden nødvendigheden af at konfigurere flere forskellige teknologier.
Men hvad er Azure Synapse Analytics helt præcist, og hvad kan du bruge det til?
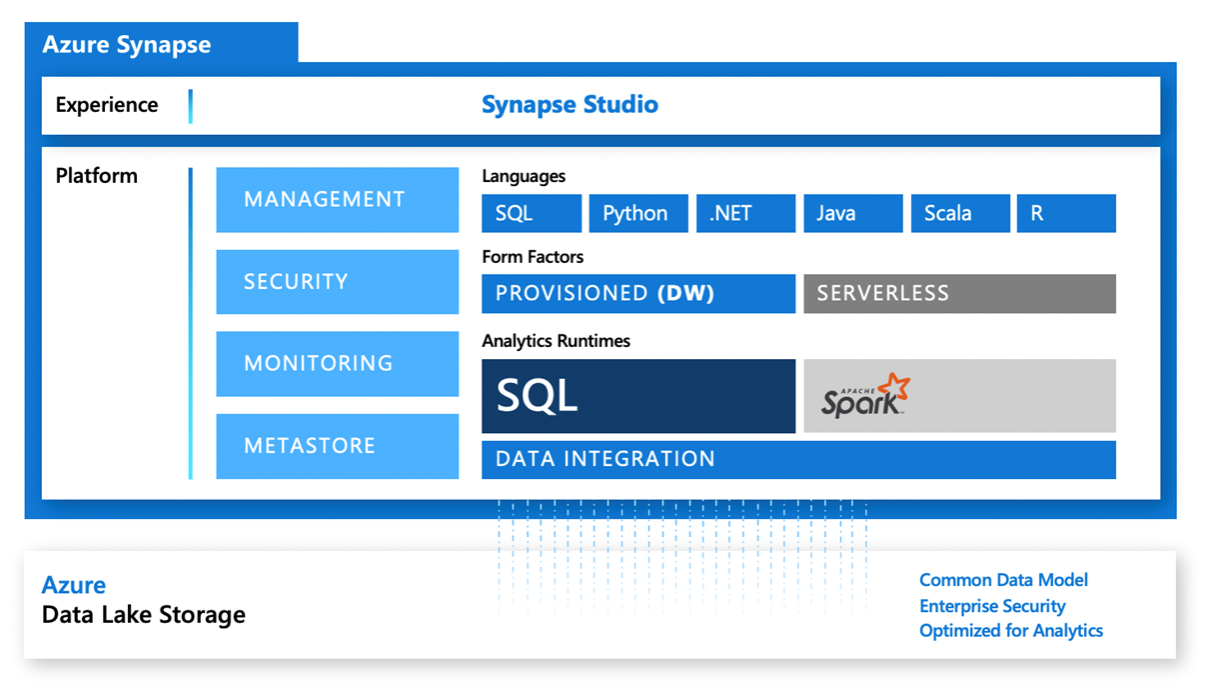
Ovenstående figur illustrerer alle komponenterne i Azure Synapse Analytics, og den bruges i vid udstrækning som en del af Microsofts dokumentation. Det er dog nødvendigt at dykke dybere ned i de forskellige komponenter for at forstå platformen til fulde. Derfor vil vi i vores gennemgang af Synapse dele de forskellige komponenter ind i deres hovedområde; storage, compute, orchestration og development environment.
Storage
Hovedlageret til Synapse er Azure data lake storage, som bruges til at lagre filbaserede data såvel som det metadatalager, der er kræves til Synapse. Denne datalake benyttes, når man har meget store mængder data eller skal behandle semistrukturerede data. Det er endda muligt at lagre data ved hjælp af Common Data Model metadata system, hvilket gør det nemt at dele data på tværs af applikationer og forretningsprocesser såsom Power Apps, Power BI og Dynamics 365.
Filbaseret lagring er dog ikke den eneste mulighed i Azure Synapse Analytics, da data lagres relationelt, når man benytter SQL Pools – hvilket vi vil vende senere i indlægget. Udover de indbyggede lagringsfunktioner er det også muligt at forbinde og bruge Spark tabeller samt forbinde til Cosmos DB gennem Azure Synapse Link.
Compute / runtimes
Der er tre primære muligheder for compute i Synapse; to af dem minder om SQL, og den tredje benytter Spark, hvilket gør det muligt at benytte flere forskellige sprog såsom Python, SQL, Scala osv.
Serverless SQL pool
SQL Serverless er en on-demand SQL pool, der allerede ligger klar, når man opsætter sit Synapse workspace. Dette gør det muligt at skrive T-SQL queries over filer, som er lagret i den tidligere nævnte data lake og kan benyttes til at udforske sine data – bl.a. gennem ad-hoc queries, som analyserer indholdet af filer, sammenlægninger, optællinger osv. Man kan også benytte SQL Serverless til at transformere data i sin data lake – f.eks. ved at konvertere CSV-filer til parquet eller ved at opsamle data til modellering og derefter lagre det i sin data lake igen.
Som navnet antyder, er denne service serverless, hvilket betyder, at der ikke kræves nogen infrastruktur. Man betaler derudover kun for query execution gennem en price-per-terabyte-prismodel. De fleste T-SQL-funktioner er understøttet, og derudover understøttes queries mod forskellige filformater såsom Parquet, CSV og JSON.
Dedicated SQL pool
Dedicated SQL pools er en mulighed i Synapse, der er ideel til data warehouse-scenarier, hvor man beskæftiger sig med store mængder af data og kompleks modellering. For at komme i gang skal man angive, hvor mange compute nodes man ønsker samt størrelsen på dem. Herefter kan man tænde for sin SQL pool, når man har behov for det. Det er også muligt enten at nedskalere eller slukke den helt, hvis man ikke længere har behov for den. Så længe ens SQL pool er tændt, betaler man pr. time.
Dedicated SQL Pools er baseret på en Massively Parallel Processing (MPP)-arkitektur, der er bygget på fundamentet af SQL Server – og som andre MPP-arkitekturer, adskiller den storage og compute. Compute bestemmes i Synapse ved en målestok kaldet ”data warehose units (DWU)”, der består af en mængde memory og compute-kerner. Dette er dog ikke en ny teknologi, men snarere en udvikling af det tidligere ”Azure SQL Data Warehouse” – og inden dette, kan teknologien spores tilbage til ”SQL Server Parallel Data Warehouse”.
Microsoft har med udgivelsen af Synapse også introduceret en række forbedringer på eksisterende teknologier. Det er blandt andet blevet muligt at køre machine learning predictions direkte i T-SQL ved hjælp af PREDICT-funktionen samt en model i ”onnx”-format og det nye COPY-statement, hvilket giver en kraftigt øget ydeevne sammenlignet med den tidligere Polybase-mulighed.
Sammenligner man Synapse med andre lignende tjenester som Snowflake, Google BigQuery og Amazon Redshift, kommer Synapse med et meget attraktivt tilbud på pris vs. performance. GigaOm udgiver en årlig benchmark performance test rapport, der sammenligner big data analytics-platforme og i deres nyeste udgivelse, kom Synapse på en andenplads. Læs rapporten her.
Apache Spark pool
Apache Spark pools i Synapse kan både bruges i data engineering- og forberedelsesscenarier samt til machine learning. Når de kører, kan du interagere med dem gennem Azure Notebooks ved hjælp af enten SQL, Python, C#, Java, R eller Scala. Du kan endda bruge en kombination af de forskellige sprog i den samme notesbog. Det er dog vigtigt ikke at forveksle dette med Databricks, da de bruger deres egen version af Spark med addons, mens denne version er specifik for Microsoft.
Ved opsætningen af en Spark pool opretter man et cluster, hvor man angiver det ønskede antal samt størrelse på ens compute nodes i forhold til processorer og hukommelse. Derudover skal man angive, hvilken version af Apache Spark man vil have samt de pakker, man ønsker tilgængelige på clusteret. At vælge en Spark-version er dog ret simpelt i øjeblikket – det er nemlig kun 2.4, der understøttes, men der kommer uden tvivl flere til senere.
I lighed med SQL pools, betaler man for Spark pools pr. time, og clusteret kan konfigureres til at pause automatisk efter et bestemt tidspunkt, så man ikke bliver opkrævet for mere, end man har brug for. Så snart de er tilknyttet en notesbog, vil de automatisk være klar til brug.
Orchestration
Til orchestration bruger Synapse en udgave af Azure Data Factory – her bliver den dog kaldet for Synapse Pipelines. Funktionerne og komponenterne i Azure Data Factory og Synapse Pipelines er dog næsten identitiske, og i fremtiden vil de være helt ens. Derudover findes funktionen ”Mapping Data Flows”, som bruger et Spark cluster til at udføre den datamodellering, man bygger i sine data flows.
Da Synapse blev tilgængeligt for alle, indførte Microsoft også support til Git Integration, hvilket oprindeligt følger med Azure Data Factory, men manglede da Synapse var i preview.
Development enviroment
Den sidste store komponent i Synapse er Synapse Studio, som er den browser-baserede ”frontend”, hvilket er det primære udviklings- og adgangspunkt for alt, hvad man laver i Synapse. Den består af en række ”activity hubs”, som vi vil gennemgå nedenfor.
Overview
Microsoft er de sidste 12 år – og senest i 2019 – blevet udnævnt af Gartner som førende i Maqic Quadrant i forbindelse med platforme til analyse og Business Intelligence. Rapporten er tilgængelig gratis fra Microsofts hjemmeside.
Manage
I Manage-hubben har man et ”one entry point”, hvor man kan konfigurere sit Synapse workspace. Ressourcer som SQL pools og Spark pools kan tændes og slukkes samt skaleres efter behov. Det er også i denne hub, at man kan oprette linked services og integration runtimes til eksterne tjenester og systemer samt konfigurere triggers til pipelines. Det er desuden her, at man konfigurerer adgangen til sit Synapse Workspace og finder lagringsindstillingerne.
Develop
Development-hubben bruges til at oprette og udføre scripts og dataflows. SQL scripts kan oprettes eller udføres på enten SQL-pools eller SQL Serverles. Derudover kan man få vist sine resultater i både tabel- og diagramform samt eksportere datasæt til CSV, JSON eller XML.
Monitor
I Monitor-hubben kan man holde styr på alle aktiviteter i ens Synapse workspace. Man har mulighed for at overvåge de aktuelle aktiviteter såvel som historiske aktiviteter inden for forespørgsler og pipelines fra Apache Spark og SQL.
Orchestrate
I Orchestrate-hubben kan man bygge og designe pipelines til flytning og transformation af data. Hubben er næsten identisk med Azure Data Factory, men objekter såsom linked services og integration runtimes er i dette tilfælde flyttet til management-hubben.
Hvad har vi lært?
Efter ovenstående korte gennemgang af komponenterne i Azure Synapse Analytics, står det klart, at det ikke blot er en service, men snarere en kombination af tjenester og teknologier, der er pakket ind i den samme workspace-oplevelse. Azure Synapse Analytics giver mulighed for at flere datakilder, både ustrukturerede og strukturerede, uanset placering, kan samles i én platform.
Med Azure Synapse Analytics kan alle typer af it-professionelle i din virksomhed nemt og sikkert samarbejde, dele og analysere data. Platformen understøtter derudover flere sprog, så uanset om du foretrækker Python, Scala eller SQL, er der stor mulighed for at gøre brug af allerede eksisterende færdigheder på tværs af din virksomhed.
Er du blevet nysgerrig på, om Azure Synapse Analytics er noget for din virksomhed? Så tager vi meget gerne en snak. Kontakt os her.